调研 RDMA 技术应用于 Redis 的杂乱笔记。
1. RDMA vs 传统计算机网络
传统计算机网络
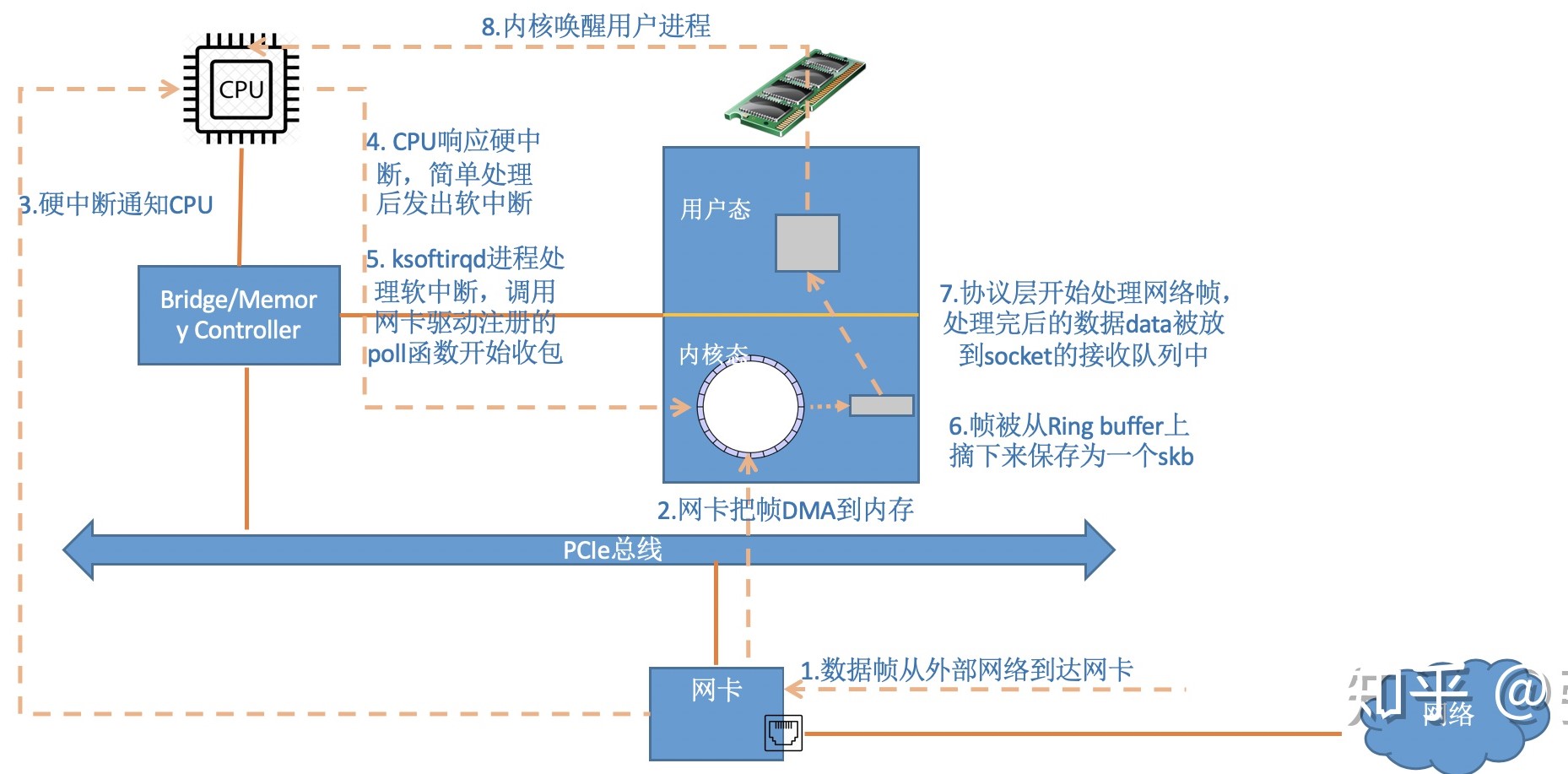
传统的计算机网络收包流程如下图所示,可以发现:
- 网络通信时,数据包每次至少需要复制 2 次
- 以字节流传递,一条消息完整地传递至对端时,接收端可能会触发多次系统调用以读取完整地消息
RDMA
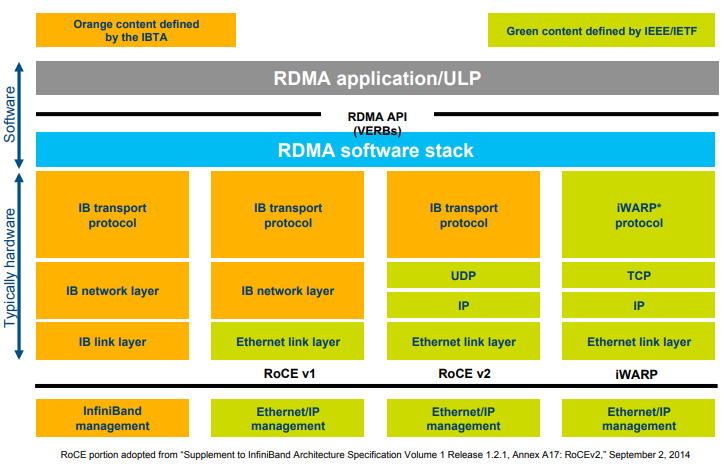
RDMA 是一种绕过远程主机操作系统内核直接访问其内存的技术。目前实现 RDMA 技术的网络协议有以下三种:
- InfiniBand:支持 RDMA 的新一代网络协议。由于这是一种新的网络协议,因此需要支持该协议的网卡和交换机。
- RoCE:RDMA over Ethernet network,允许在标准以太网上(交换机)使用 RDMA 技术的网络协议,需要网卡必须是支持 RoCE 的特殊网卡。
- iWARP:RDMA over TCP,允许在标准以太网上(交换机)使用 RDMA 技术的网络协议,只不过网卡要求是支持 iWARP 的(如果使用 CPU offloads 的话),否则所有 iWARP 栈都可以在软件中实现,但失去了大部分 RDMA 的性能优势。
三种协议使用的 API (verbs) 是相同的。
我们以 InfiniBand 为例,InfiniBand 通过在应用程序之间创建 channel 连接 (故可称为 Channel I/O) 以提供 messaging service 进行通信,如下图所示:
Queue Pairs(QPs):指 channel 的端点,每个 QP 包含一个 Send Queue(SQ) 和一个 Receive Queue(RQ)- 通过将 QPs 映射为应用程序的虚拟内存空间,以实现应用程序直接访问 QPs
- 由 HCA(Host Channel Adapter) 提供地址转换
- InfiniBand 提供两种 transfer semantics 用于传递消息
- channel semantic:
SEND/RECEIVE- 接收方预先在自己的 RQ 中定义数据结构
- 发送方无需知道接收方 RQ 中的数据结构,仅负责调用
SEND发送消息
- memory semantic:
RDMA READ/RDMA WRITE- 接收方在自己的虚拟内存空间中注册一个 buffer,并将控制权交予发送方
- 发送方通过调用
RDMA READ或RDMA WRITE读写该 buffer
- channel semantic:
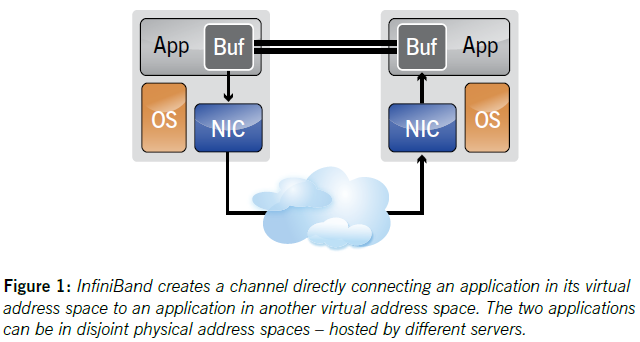
可以发现,InfiniBand 通过将网络协议固化于硬件上,从而实现 RDMA 技术,其带来以下优势:
- Zero copy:应用程序可以在没有网络软件栈参与的情况下执行数据传输,并且数据被直接发送至对端缓冲区,无需在网络层之间进行复制
- Kernel bypass:应用程序可以直接在用户态执行数据传输,无需系统调用,从而无需执行上下文切换
- No CPU involvement:应用程序可直接访问远程主机的内存而无需远程主机的 CPU 参与
- Message based transactions:数据以消息的形式传输,而不是以字节流的形式,从而应用程序无需执行将字节流切分为不同消息的过程
- Scatter/gather entries support:RDMA 原生支持分散/聚合,即读取多个内存缓冲区并将它们作为一个流发送,或接收一个流后将其写入多个内存缓冲区中
其中 zero copy 和 kernel bypass 是 RDMA 具有低延迟、高吞吐和降低 CPU 使用率特性的关键所在。
2. 应用 RDMA 技术
想在 Redis 中利用 RDMA 技术的优势,主要有以下两种方式:
- 软件重构:使用 RDMA API 重构应用程序
- 优点:可以结合 RDMA 网络的硬件特性,调整软硬件结构,从原语使用、数据流优化、协议设计等方面重新设计软件逻辑,从而充分发挥 RDMA 网络的硬件优势
- 缺点:侵入式开发,后续跟随官方 Redis 的更新较为复杂,门槛较高 (在学了,在学了.jpg)
- 简单的网络替换:启动应用程序时,加载 libvma 动态库
- 优点:操作简单,无需修改应用程序,方便跟随官方 Redis 版本更新
- 缺点:无法充分发挥 RDMA 网络性能
3. 测试结果
以下测试结果是在服务端加载 libvma 动态库的情况下测得:
- 当客户端数量和数据量大小变化时,使用 RDMA 对 Redis 的吞吐量和延迟均有巨大的提升: ops 约为未使用 RDMA 的 2 倍,延迟约为 1/2.
- 可以发现在客户端线程数增加时,虽然吞吐量和延迟的提升和不使用 Pipeline 场景类似,但是 p99/p100 Latency 在线程数增加时,使用 RDMA 时延迟值的增长较未使用 RDMA 更为缓慢
- 但是在使用 Pipeline 的情况下,使用 RDMA 对 Redis 的性能提升不明显: 数值上无明显差异